Webスクレイパー APIs
世界中の数百の公開ウェブサイトからリアルタイムでデータを抽出。APIを通じて構造化データに迅速にアクセスし、開発と保守のコストを削減します。

開発やセルフホスト型サーバーは不要です。
人気プラットフォームを幅広くカバー(例:Amazon、YouTube)
構造化データ出力(JSON / HTML形式)
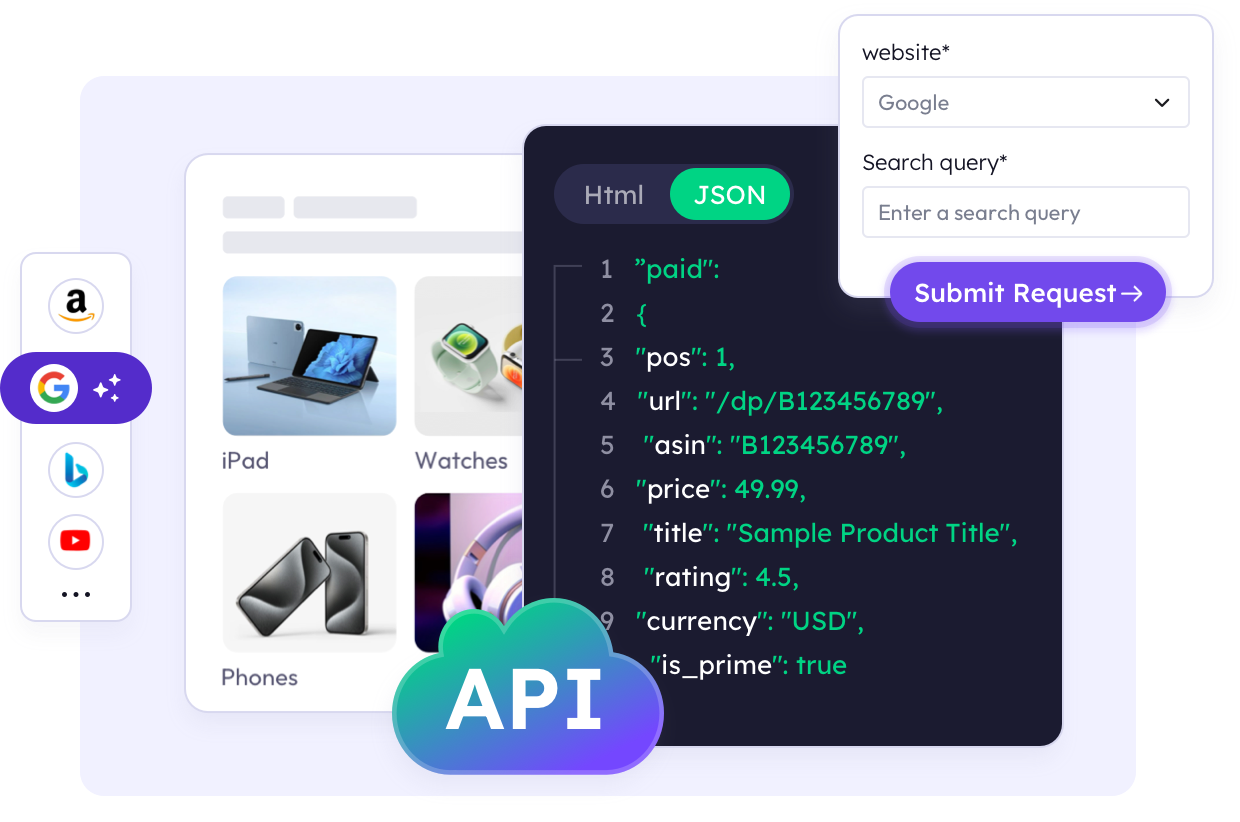
あらゆるスクレイピングニーズに対応する豊富なテンプレートライブラリを探索しましょう。
データなし
難易度の高いウェブサイトからのデータ取得もこれまでになく簡単に。実用的なコードサンプルでWeb Scraper APIの機能を体験してください。
curl -X POST https://scraper.smartproxy.org/v1/query -H "Authorization: Basic XXX" -H "Content-Type: application/json" -d "{"source":"amazon_search","context":{"keyword_list":[{"keyword":"MacBook"}],"start_page":1,"pages":2},"geo":"US"}"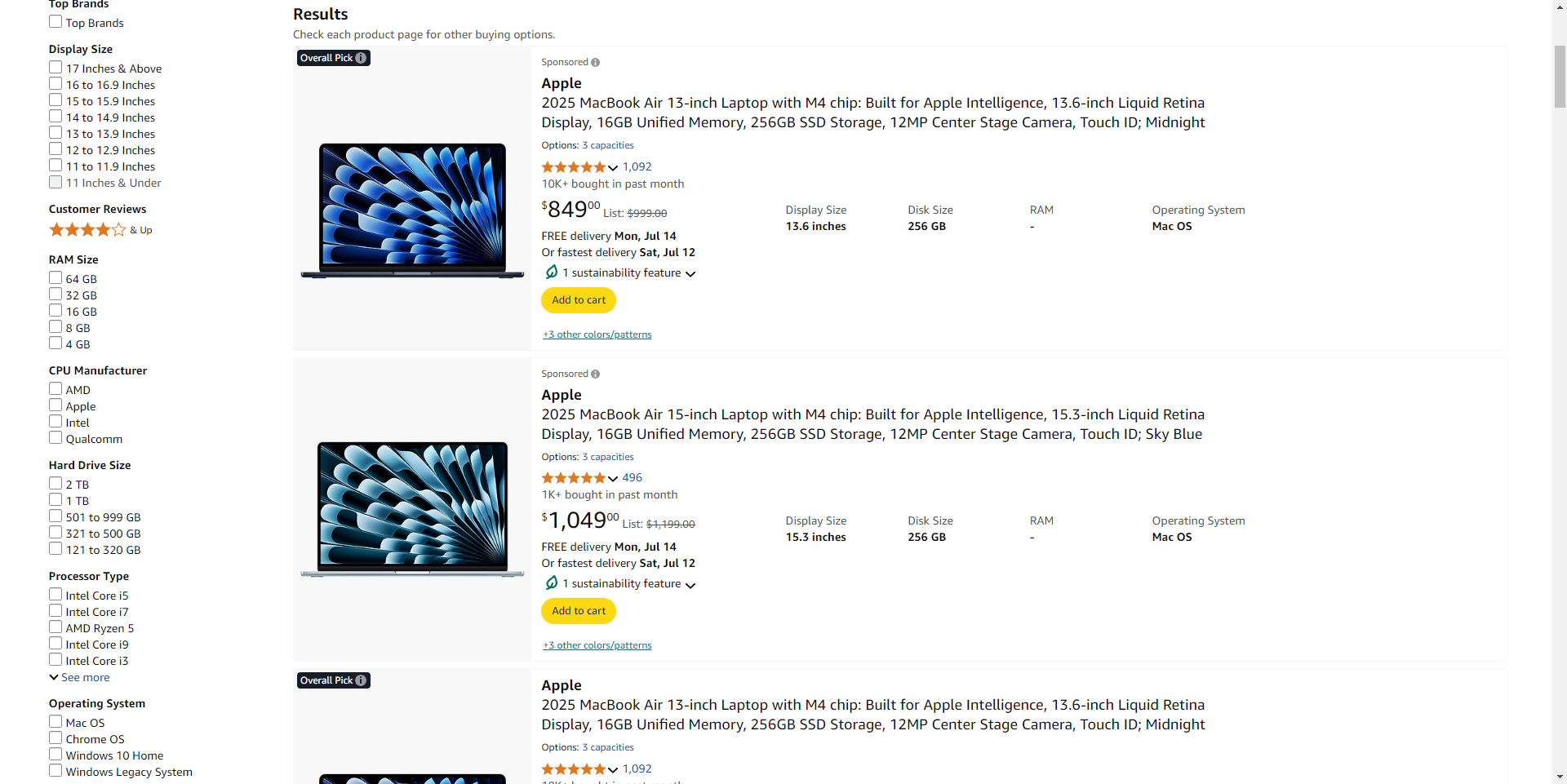
エンタープライズ向けのデータソリューションで、よりスマートな成長を実現。Web Scraper APIを無料でお試しください—ビジネス要件に合わせてカスタマイズ可能です。
$-/1K結果の価格プランを取得
注意: 金融や政府関連など、ポリシーで制限されているウェブサイトへのアクセスはサポートされていません。
ご利用可能なお支払い方法:
人気地域:US,GB,CA,IN,BR,MX
住宅用IPローテーション
HTTP/SOCKS5対応
国・都市レベルでの位置指定
平均成功率99.5%
専任カスタマーサクセスマネージャー
API&ユーザー・パス認証対応
IP利用率99.9%
世界有数のプロキシインフラを活用し、安定したパフォーマンスと障害の最小化を実現します。
本番環境対応APIでスクレイピングを自動化し、リソースを節約しメンテナンスも削減。
データ需要に合わせてスクレイピングプロジェクトを簡単に拡張し、最適なパフォーマンスを維持。
データ構造やパターンを検出し、効率的かつ的確なデータ抽出を実現。
サーバー負荷を軽減し、大量スクレイピングタスクのデータ収集を最適化。
生のHTMLを効率的に構造化データへ変換し、データ統合や分析を容易にします。
データの信頼性を確保し、手動チェックや前処理の手間を削減。
包括的・スケーラブル・コンプライアンス対応のウェブデータ抽出
どのウェブサイトからでも構造化データを取得—必要なドメインとデータポイントを伝えるだけで、精密に設計された専用スクレイピングAPIソリューションを提供します。ご希望のフォーマット(JSON、NDJSON、CSV)を選択し、WebhookやAPI経由でデータを受け取り、ワークフローにシームレス統合。

プロキシ不要・ブロックなし—自動アンブロック&自動化機能でどこからでも簡単にデータ収集。完全自動化で信頼性が高く、時間も節約—データをシームレスにお届け。
データ保護規則(GDPR、CCPA)を厳格に遵守し、ユーザーデータの安全性とプライバシーを確保します。

企業と個人向けのSmartProxy、安定した安全で高度にカスタマイズ可能なスマートプロキシとスマートプロキシサービスを提供。
Proxy Knowledge Guide
If you can't find something or need assistance, please contact us at [email protected]
ポリシーにより、中国本土ではご利用いただけません。 ご理解ありがとうございます!




